Meer CPU, minder performance
Wanneer je merkt dat je server veel resources verbruikt is een logische volgende stap om meer hardware tegen het probleem aan te gooien. En soms geeft dat, in ieder geval tijdelijk een verbetering. Het tegendeel kan echter ook waar zijn. Een klant legde mij ooit de situatie voor waarbij het laden van een grote feitentabel langer duurde nadat er meer processoren waren toegevoegd. Op het eerste gezicht onverwacht maar wanneer je er dieper induikt blijkt het precies zoals verwacht.
Het scenario
In dit geval ging het om het laden van nieuwe gegevens in een datawarehouse. Iedere dag worden wijzigingen van een bronsysteem geladen en dan volgens bedrijfsregels wordt deze data in een datawarehouse geladen. Je verwacht sowieso dat dit zware processen zijn met veel joins en, zeker in het geval van een feitentabel veel data. Dit proces werd nauwkeurig gemonitord en zo was dus direct zichtbaar dat de verwerkingstijd opliep. Dit viel samen met het toevoegen van processoren. Dit vermoeden werd versterkt omdat het verwijderen van de processoren een performance verbetering gaf.
Analyse
Dit probleem was reproduceerbaar en dat helpt enorm. Niet alleen was het reproduceerbaar op de productieomgeving. We konden zelfs op een testsysteem dit scenario nabootsen. Het voordeel hiervan is dat je ongestoord kunt testen en aanvullende gegevens verzamelen zonder een productieproces in de weg te zitten. We haalden een van de zwaardere query's uit de hele set om die verder te analyseren. Nadat we van beide scenario's een query plan hadden verzameld konden we die met elkaar gaan vergelijken.
Gelukkig waren beide plannen ook verschillend. In het plan met minder processoren werd direct een grote tabel gefilterd om daarna met een subset van die data de overige joins op te bouwen. In het plan met meer processoren werden eerst de dimensietabellen opgehaald om zo de feitentabel te filteren. Het verschil is dat het tweede plan minder geheugen nodig had. Minder geheugen klinkt misschien efficiënter maar de data moet ergens vandaan komen. En de twee query had wel veel hogere kosten wat je rustig kunt vertalen naar meer resources en dus langzamer.
Omdat de executieplannen voorhanden waren en er verder aan de hardware en software kant niets veranderd was anders dan het bijplaatsen van processoren was het vooral zoeken naar de verschillen. Er was één verschil dat direct opviel. Dat was EstimatedAvailableMemoryGrant. Zoals onderstaande afbeeldingen laten zien was die op de server met minder processoren hoger dan op de server met meer processoren. Niet alleen dat. Het verschil is vrijwel gelijk aan de procentuele toename van processoren.
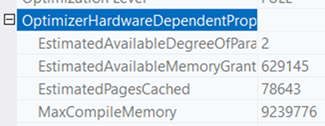
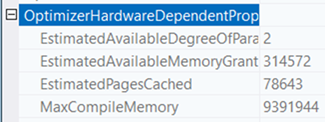
Omdat de query optimizer inschat dat er meer geheugen beschikbaar is, wordt gekozen om vrij vroeg een grote staging tabel te filteren en daar dan de dimensies bij te zoeken. Dit is dan de input voor de feitentabel. Vanwege de hoeveelheid data kiest de query optimizer voor een Hash Match en dat betekent dat er veel geheugen nodig is.
Wacht. Er is meer
Het executieplan toonde nog iets opvallends. Als je kijkt naar de grootste tabel die geladen wordt zie je dat dit gaat om miljoenen rijen uit een veel grotere tabel. Er zijn meerdere processoren beschikbaar dus zou je verwachten dat je een parallel plan krijgt. Zeker bij analytische workloads is dat gebruikelijk. De optimizer kijkt naar de kosten van de query om een parallel plan te overwegen. In dit geval waren de kosten 1894,83 wat meestal een parallel plan oplevert. Gelukkig laat het executieplan ook zien waarom er geen parallel plan gekozen werd.

Maar in alle eerlijkheid. Hier heb je nog niet zo heel veel aan. Dit plan is ook gemaakt op een oudere versie van SQL Server (2017). Vanaf SQL Server 2022 is er meer informatie beschikbaar. In dit geval was de schuldige echter makkelijk aan te wijzen. Een scalar functie. Functies zijn berucht om allerlei negatieve effecten. Zeker in eerdere versies van SQL Server.
De oplossing
Weten wat het probleem is geeft niet direct de oplossing. En er zijn meestal meerdere oplossingen mogelijk. De ene oplossing geeft meer lucht op de korte termijn terwijl de andere oplossing meer tijd kost maar op de lange termijn echt het probleem oplost.
Korte termijn: meer hardware
Een kortetermijnoplossing is om geheugen bij te plaatsen. In dit geval ging het om een virtuele server en was het vrij eenvoudig om meer geheugen toe te wijzen. De toename van geheugen moet gelijk zijn aan de procentuele toevoeging van processoren. Bijvoorbeeld van 2 cores en 16gb geheugen naar 4 cores en 32gb geheugen. SQL Server ondersteunt zelfs hot add memory dus je kan dit doen zonder downtime.
Langere termijn: het probleem oplossen
Het echte probleem zit in de functie. Want de kortetermijnoplossing is, tsja een oplossing voor de korte termijn. De Hash Match volgt op een clustered index scan die hier een tabel van 12 miljoen rijen filtert naar 2 miljoen. Maar die tabel zal blijven groeien. Het is dus niet ondenkbaar dat op een punt in tijd ook het extra geheugen te weinig is en de kortetermijnoplossing weer meer geheugen is.
Meestal kan een functie wel herschreven worden of zelfs achterwege gelaten. Door de functie te optimaliseren krijgt SQL Server de kans om een parallel plan te overwegen. Ook het upgraden van SQL Server naar een nieuwere versie kan een verbetering geven met behoud van de functie.
Tot slot
Zo zie je dat het ogenschijnlijk onschuldig toevoegen van meer processoren toch een behoorlijke impact kan hebben op een proces. Aan de andere kant was dit ook een sluimerend probleem. Met de hoeveelheid data waar nu mee gewerkt werd was er geen probleem. Maar door de processoren te verdubbelen werd het probleem ineens zichtbaar. Een probleem dat mogelijk ook naar boven was gekomen wanneer de hoeveelheid data behoorlijk was toegenomen.